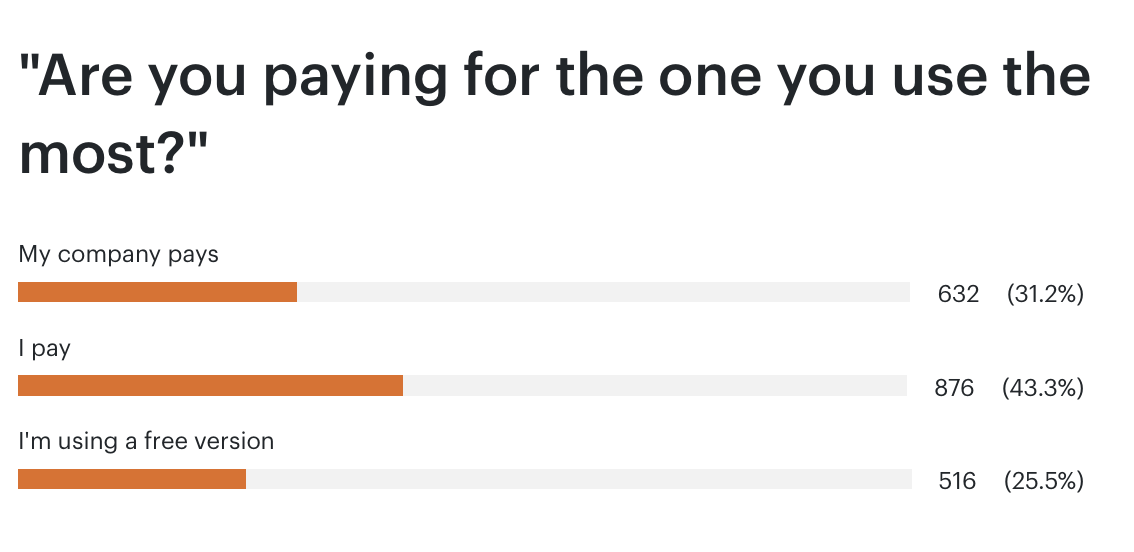7 September 2025
News
Google wins an antitrust round
Google has lost two US competition cases this year: adtech and search. In the search case, Google lost in the summer; each side proposed remedies, and now the judge has come back with remedies. On one hand, Google is banned from signing exclusive search distribution deals with Android OEMs and telcos and must provide some kinds of search stream data to competitive search engines. But on the other hand, it is not obliged to split off Chrome or Android (which the DoJ asked for, but whose consequences were very hard to understand), and it can continue paying revenue shares for distribution deals, which means that it can carry on paying Apple ~$20bn a year to be the default on the iPhone. There’s also no obligation for choice screens, a solution that some academics seem to love but which don’t actually achieve anything.
This is clearly a win for Google: antitrust activists are very upset, but it was always vastly easier to say that some of the things Google did to protect its market share were illegal than to identify practical, realistic ways to create a viable competitor to Google Search. But meanwhile, the judge spent a lot of his ruling talking about the emergence of generative AI as a major change in the nature of search, none of which had been prevented by any of Google’s conduct or enabled by the DoJ. I wrote about this dynamic quite a lot a while ago: Microsoft didn’t lose its dominance of tech through antitrust, but because its dominance of the old thing stopped mattering once the new thing happened.
Finally - that adtech case is still going on, with the remedies hearings for that starting later this month… and meanwhile the EU just fined Google €3bn over similar issues. RULING, EUROPE
Apple does search?
So far, Apple has been treating generative AI as a technology to drive new individual features (eg email summarisation, photo editing), and as as a way to power a rebuild of the ‘Siri’ personal assistant that handles your data (the thing that’s delayed). Now, though, Bloomberg reports that it’s also looking at a full-scale model with knowledge of the world and web search, a much more direct alternative to ChatGPT. That might not necessarily look like a chatbot, with a GUI and product design layer in front, and it might be powered by Google’s Gemini.
Compare and contrast this with the fact that Google will now (barring appeals) be free to pay Apple a $20bn annual rev share, which is a pretty powerful incentive not to do its own web search, or at least not directly, and of course that was part of the point of the original lawsuit. (Side note: I am old enough to remember when we learnt about Apple plans at Apple events, not in Bloomberg’s reporting). LINK
Product strategy at OpenAI
OpenAI’s new head of product, Fidji Simo, has arrived from Instacart, and things are changing. Kevin Weil (head of product) had previously been going to work with her in some way, but now he will run a new ‘AI for Science’ team (which sounds pretty vague). A bunch of other people have been shuffled, and OpenAI will work on its first vertical product, a recruiting tool. Remember when generative AI meant you could use the chat as a single unified UX? Maybe ‘generative UI’ will unify this again, but this also reminds me of the way that Google thought you could do every kind of search with the same UX and in the end had to create vertical search for things like flights instead. INTERVIEW, JOBS TOOL, COVERAGE
Meanwhile, OpenAI also bought Statsig, an app analytics platform, for $1bn in stock (I have no idea), and the FT reported it’s started working on its own ASIC (custom AI chip for data centres) in partnership with Broadcom. What will OpenAI’s deal with Microsoft look like once it’s spending $25bn or $50bn a year on its own infrastructure? STATSIG, BROADCOM
AI Rights
Warner Brothers is suing Midjourney for letting users make images of its characters (Batman, Bugs Bunny, etc.), following Disney and Universal earlier this year. There are lots of quite subtle legal distinctions involved. LINK
Meanwhile, Anthropic settled a lawsuit over its use of a repository of pirated books as training data, agreeing to pay $1.5bn. When you’ve just raised another $13bn at a $188bn valuation, sometimes it’s better to pay the speeding ticket than fight it. Meta won a related ruling this summer, which leaves this space uncertain. LINK
The week in AI
Marc Benioff says that AI automation means Salesforce has replaced 4,000 customer support jobs. Take with a pinch of salt given that Salesforce is selling that tech itself. LINK
Apple’s struggle with foundation models gets the headlines, but the AI team keeps shipping good stuff lower down the page - this week, some impressive on-device video captioning models. LINK
China has a new law requiring all AI-generated images to be labelled. LINK
The Browser Company, which is behind a couple of interesting web browser projects with fans in tech but that never really got traction, was bought by Atlassian. Worth thinking about as the AI lab companies all look at web browsers themselves. LINK
OpenAI is hiring a content marketing strategist. Apparently you can’t use ChatGPT to write everything after all. LINK
Muskland
Noted with amusement: Tesla’s board has proposed a new pay package for Elon Musk worth up to $900bn, it the market cap rose from $1.1bn now to $8.5tr. Some of this is a percentage game, yes, but equally, should you really have to offer your checked-out CEO a trillion dollars to get him to come back to the office? The broader context, perhaps, is that Musk is now spending a lot more time talking about future, blue-sky ideas for Tesla, like humanoid robots, than actual cars, where the company has been idling for years and doesn’t have a good answer to the flood of Chinese EVs. LINK
Ideas
OpenAI has a fascinating new paper on AI ‘hallucinations’ arguing that it’s mostly a problem of incentives in training: a model will get better aggregate benchmark scores if it guesses when it doesn’t know, because then it will sometimes be right, than if it says it doesn’t know, in which case it will never be right. In other words, model results should put more weight on confidence for any given answer and less on higher average scores. Seems a little neat, though. LINK
A good analysis of the problems with that report from a lab connected to MIT that claimed ’95% of AI projects fail’ (PSA: the report didn’t actually contain that number, and didn’t give any methodology or definitions). LINK
Google’s SEO-whisperer on how to do ‘GEO’ (‘generative engine optimisation’) - basically, don’t worry and just make your pages good (which is what Google has always said about SEO as well). LINK
Does LLM traffic convert better than search? LINK
The AI ‘jailbreak’ arms race - when you trick the AI into doing things that the model company doesn’t want it to do. LINK
Related: Meta released an OSS project for a ‘firewall’ to catch jailbreak attacks. LINK
A case study using voice AI in recruitment calls that claims this works better than human screening calls. LINK
What happened to narrative podcasts? LINK
Analysing Chinese cooperation between military and civil AI. LINK
Perplexity’s ad chief left (mostly, I suspect, because with only ~20m users and a completely new kind of product, it was hard to get advertisers’ attention). LINK
A profile of the cluster of Chinese ‘Little Dragon’ AI startups around Hangzhou. LINK
The IAB has a mapping of AI use cases in AI. LINK
I forgot to link to this last week - the FT has a story that a bunch of the AI researchers that Mark Zuckerberg hired for tens or hundreds of millions of dollars quit after a few weeks, or didn’t even turn up. Culture is hard, but this is a ridiculous way to behave. LINK
Outside interests
The Kong dog toy was originally a VW axle stop? LINK
The rise and fall of musical ringtones. LINK, CHART
China’s pre-digital fonts. LINK
Data
How often do LLM assistants hallucinate links? LINK
The state of TV VOD subscriptions. LINK
Another study trying to work out if employment changes correlate with generative AI. What puzzles me about all of these is that the observed declines in employment all start in late 2022 or early 2023, before most people outside Silicon Valley had even heard of ChatGPT… while there were other significant changes in the USA in late 2022. LINK
Column
Reader survey results
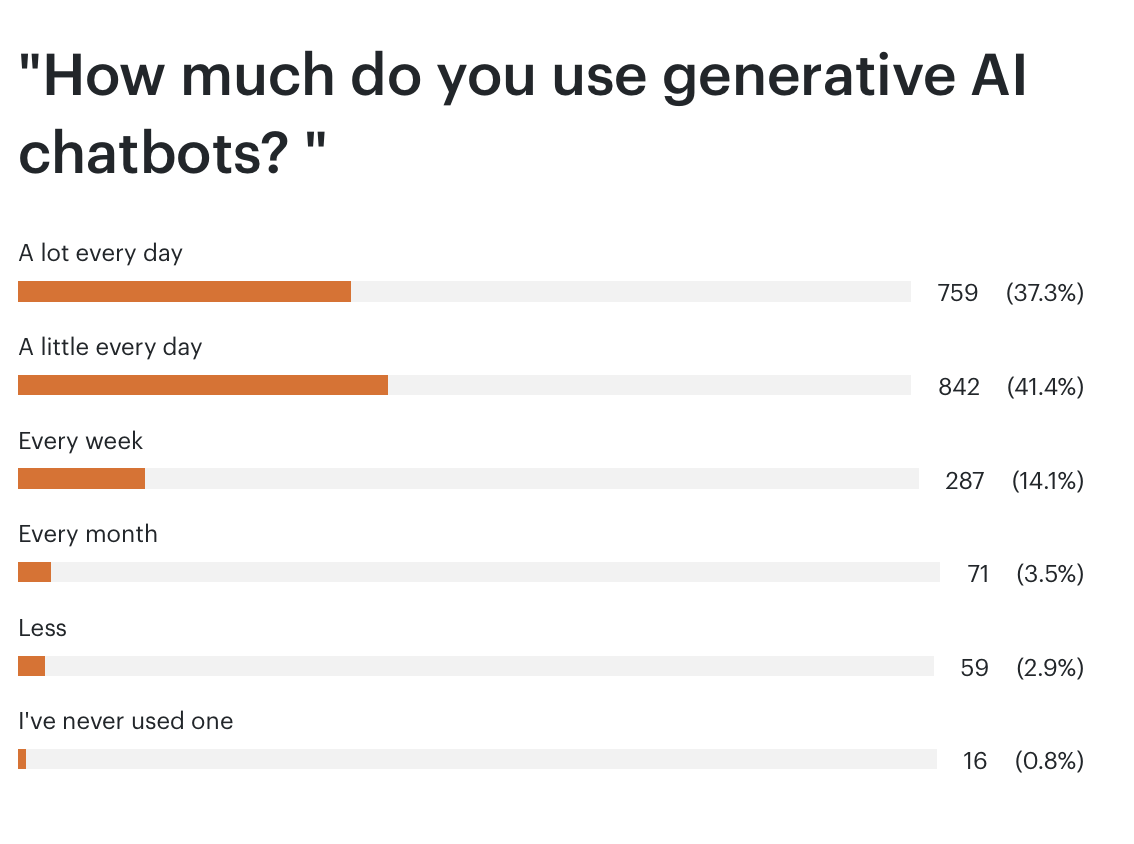
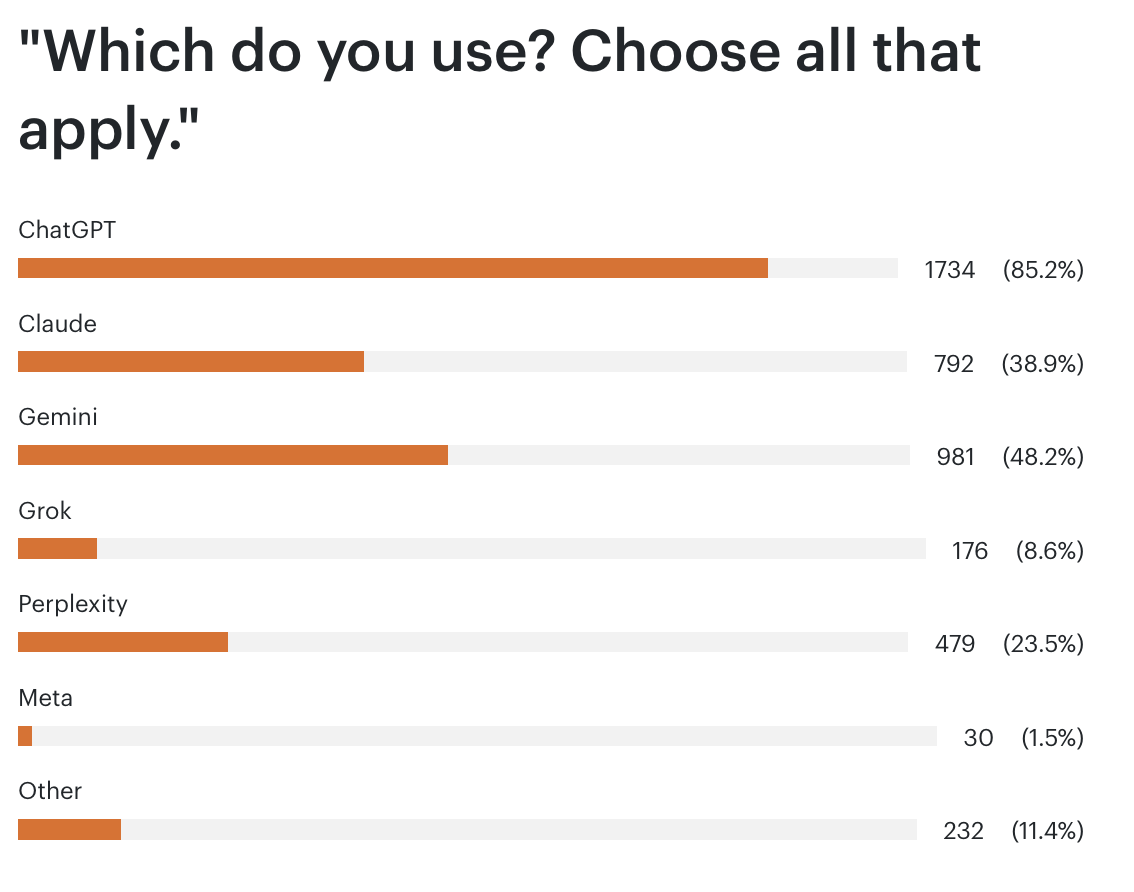
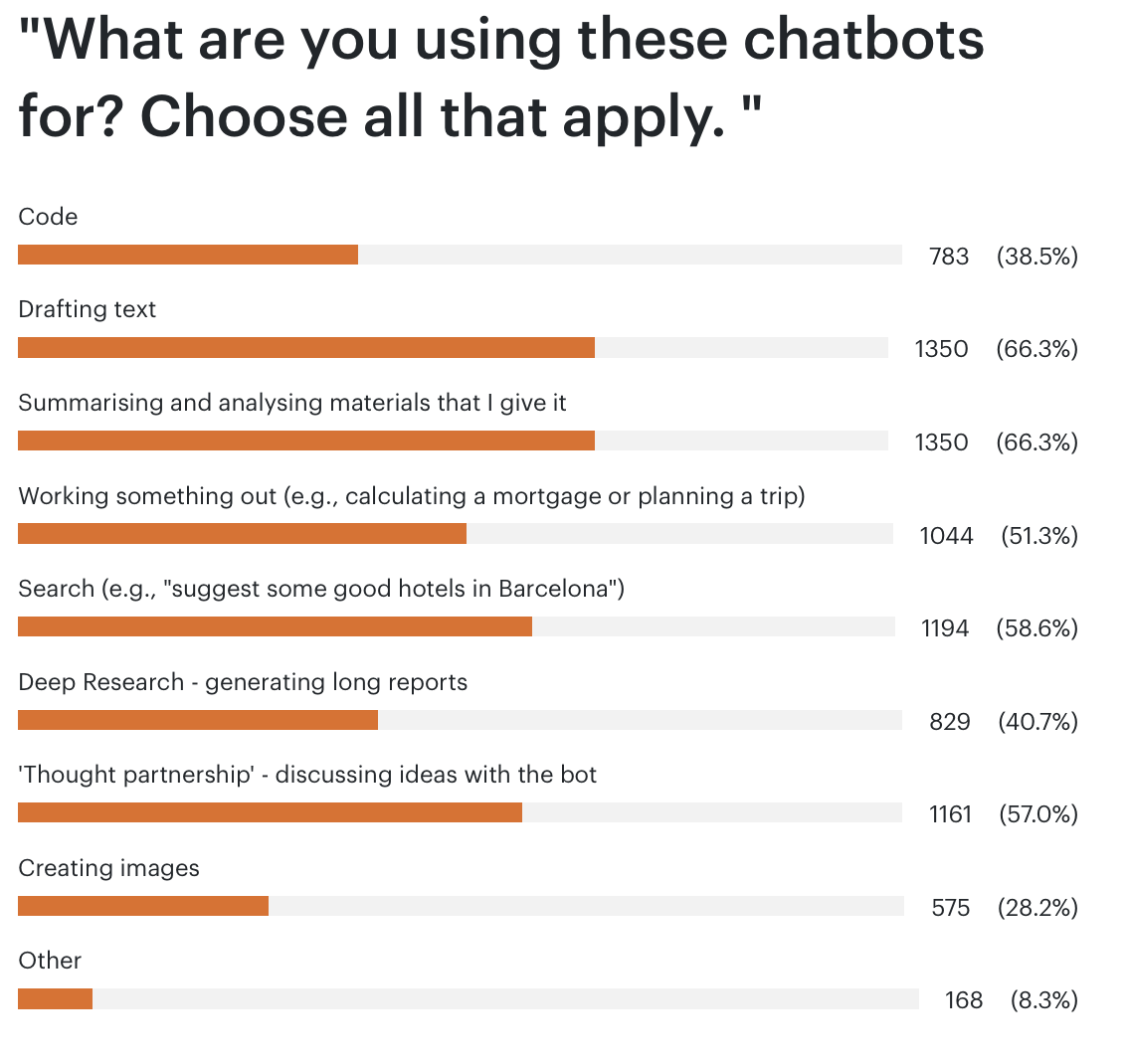
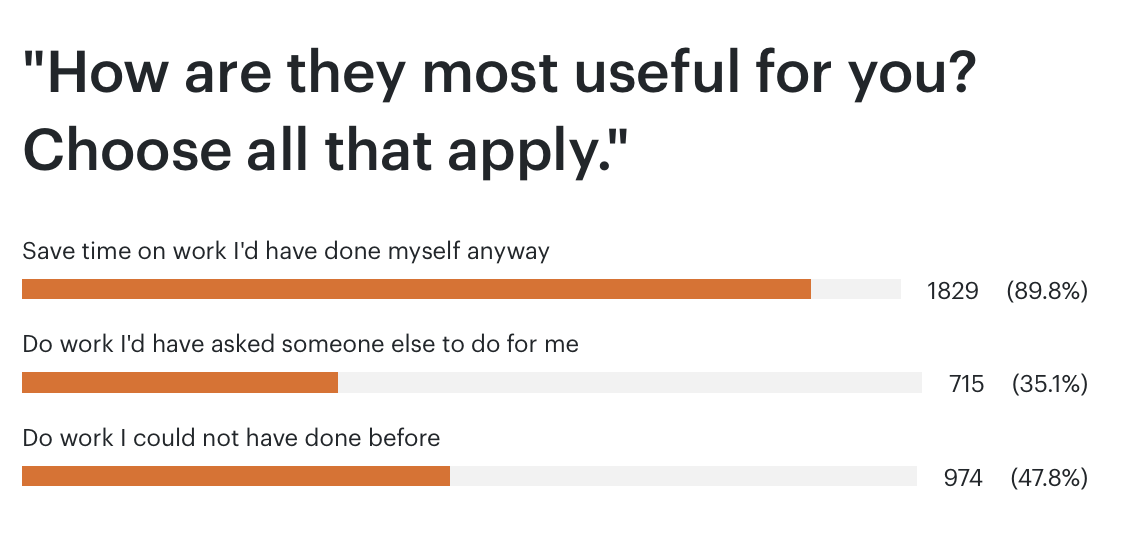
Last week I ran a reader survey across my premium and free newsletters, asking some level-setting questions about how my readers are using generative AI. This is a combined audience of about 170k people, with a 50% weekly open rate (90% for premium), heavily concentrated in tech and professional services (there are a couple of thousand Google email addresses on the free list, for example), so this is very self-selected. I’ve pasted in all of the results below. Some observations:
This is (as one would expect) much higher adoption than the general population even in the USA, where we still seem to have only 10-15% DAU use overall, and perhaps double that in tech and professional services.
Most people are using multiple chatbots, which again is different: in the broader market it looks like ChatGPT has 10x more users than anything else.
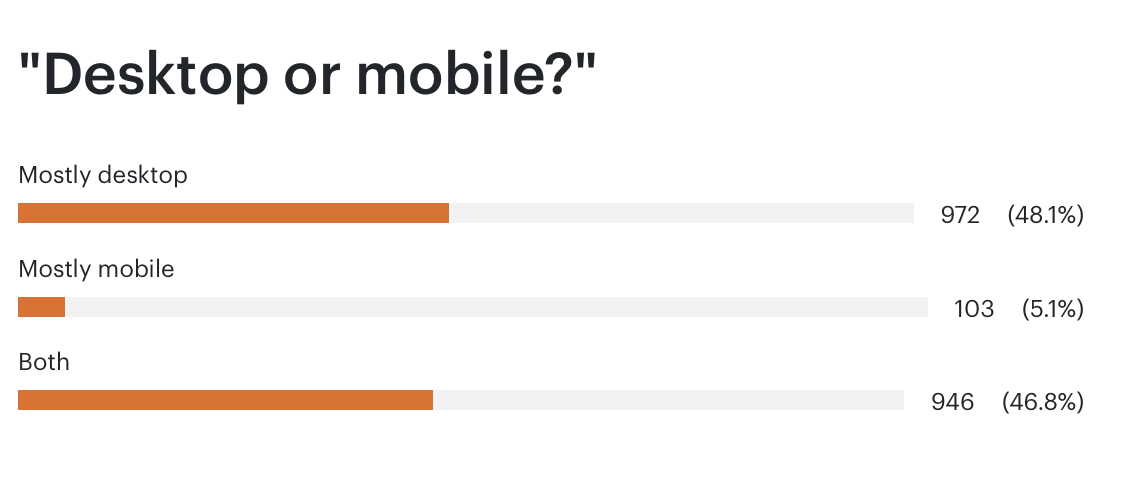
Most use is on desktop, not mobile, which is an interesting shift in the weighting of adoption, but also reflects what you use this for.
A quarter of people are using the generally much more limited free versions, which means they're not necessarily seeing the real current capability.
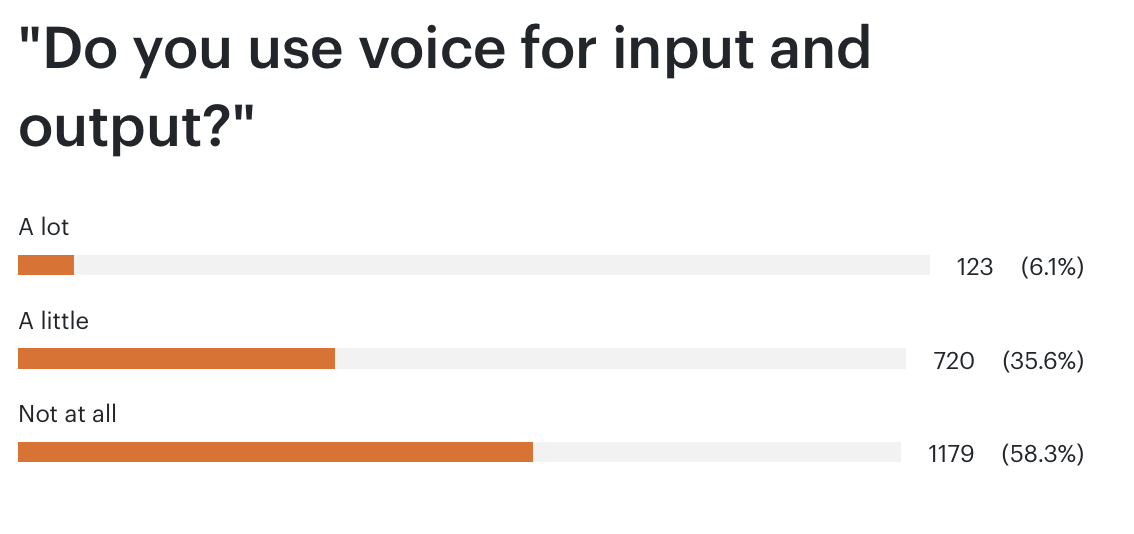
I know a couple of people who say they have long conversations with ChatGPT on walks. Most of you aren’t doing that - voice use is not strong.
Let me know if you have suggestions for a follow-up survey (or want to advertise to that audience. Sundar - I have a corporate plan ;) ).