Predicting AI job exposure
It would be really nice if we had some way to analyse which jobs, companies and industries were exposed to AI, and if we could assign scores, and build charts, and map that against the progress of large language models. We know, in principle, that like every other big wave of technology, AI is bound to destroy some jobs and create others. But which ones? In the last three years a bunch of people have been very busy crunching census data, making tables and building viral charts.
I think this is mostly impossible: I think this is an exercise in predicting something that cannot be predicted.
The simplest way to see the problem is to back-test this against other big technology shifts in the past. Some of the industries that should have suffered most ended up much bigger, and some of the industries that did suffer most should have been immune.
Hence, we spent a century automating accounting: we built calculating machines, punch cards, mainframes, data processing, databases, PCs, spreadsheets, ERPs, cloud… in fact, we built half of the tech industry around automating this. Yet the number of accountants kept going up.
This is high-level survey data, but you can see much the same thing at the micro level. The next chart is about as specific as it gets: 50 years of financial automation doesn’t seem to have hurt the market for CPAs. If you’d done any kind of analysis of professions exposed to automation from computing, this should have been at the top of the list. Dan Bricklin talks about CPAs in the late 1970s using VisiCalc to do one-month projects in a few days. And yet, look what happened.
I think there are three things to point to in this chart. The first is that technology was not the only variable: changes in regulation produced new accounting requirements that led to a one-off surge in CPA hiring (this is why economists say ceteris paribus). Second, within the automation conversation itself there is the much-discussed Jevons paradox, which is really applied price elasticity: if you make it cheaper to do something, do you do the same for less money (or resources, or employees), or more for the same money, or does a new ROI mean you do more for more money? If a DCF takes a week and then it takes 30 seconds, you probably do more DCFs. ‘Exposure to automation’ might mean more work, not less.
But then, the more important story is that if you automate something that used to be expensive and time-consuming and it becomes cheap and quick, that probably unlocks other things. If analysis becomes cheap and easy, you do much more analysis, and mostly that’s also a different kind of analysis. Accountants today aren’t doing exactly the same work that they did in 1970 or 1980 ‘but more’ - they’re still called ‘accountants’ but the job is different. New technology often starts out being used for ‘the old thing but more’, but it rarely ends up like that.
Indeed, if you dig into the detail of the Census data, then ‘accountants and auditors’ itself is a fairly stable category, but all around that term there are lots of other finance job categories that appear and disappear over time. The job of “Billing, posting and calculating machine operator” appeared in the stats for a decade or so and then disappeared again. How often did that represent someone who started their career as a stock clerk, then became a ‘posting machine operator’ because that was how you did stock-keeping, and then retired as a stock clerk again when that was absorbed into software and the Census didn’t create a category for ‘PC operator’? Equally, there’s still a category for ‘data keyer’ but not for ‘ERP operator’. The same person doing the same actual job (or rather, serving the same business purpose) gets different job titles over time, while ‘accountants’ have the same job title while doing different things.
Then, I think there's a second problem that comes up in back-testing: the job might not change at all, but the business might change underneath you.
The internet didn't really change what it took to be a good journalist or a good A&R scout, but the job of journalism was paid for by a light manufacturing and trucking operation with (in the USA) a local monopoly on classified ads, and the record executive’s salary was paid by manufacturing and shipping small pieces of plastic and aluminium foil. That was a whole other thing that would not be captured in any analysis you tried to do of what it is to be a copy editor or a sound engineer. The internet decoupled a class of business where the product and the job were not affected by the internet but the business was.
It seems to me that we should expect the same thing to happen with AI: how many people have a job that has very low exposure to AI, but the business depends on some other job that is hugely affected by AI? How many people have a job doing something that’s very hard for AI to match, but their company’s defence against competition is that they also have lots of buildings full of people doing something very boring? AI will take a bunch of stuff that used to be expensive and make it very cheap or free - what does that unlock and what does that break, and how many jobs is that?
Third, continuing the theme of big and unpredictable effects of past technologies, how does your analysis handle Uber? I worked in mobile in the 2000s and we all spent a lot of time talking about location data, but it didn’t occur to anyone that this might be an issue for taxis - you might have suggested more efficient dispatch, but no-one was considering that this could totally change the nature of the job (and make a bunch of $1m medallion mortgages worthless). If you’d been calculating ‘internet exposure’ by occupation in 1995 or ‘smartphone exposure’ in 2005 (yes, we had smartphones before the iPhone), are you confident you’d have put taxi drivers on the list?
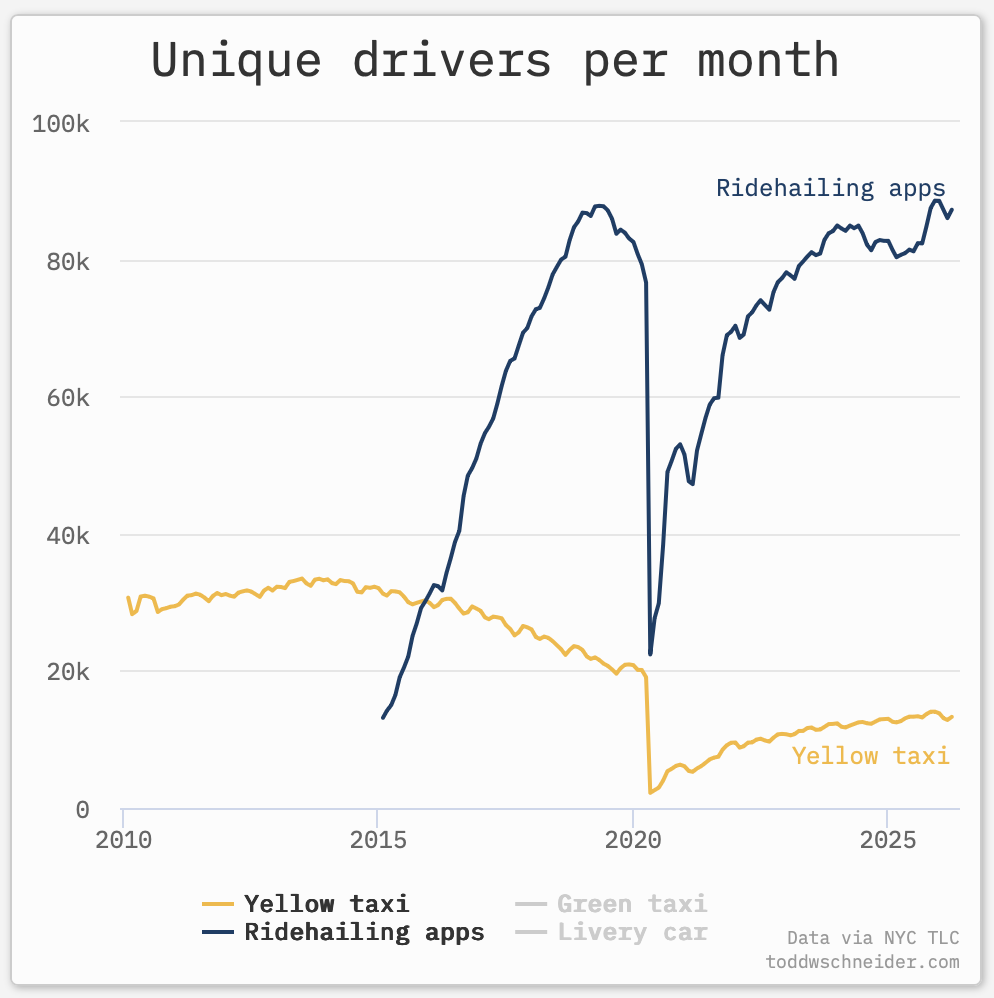
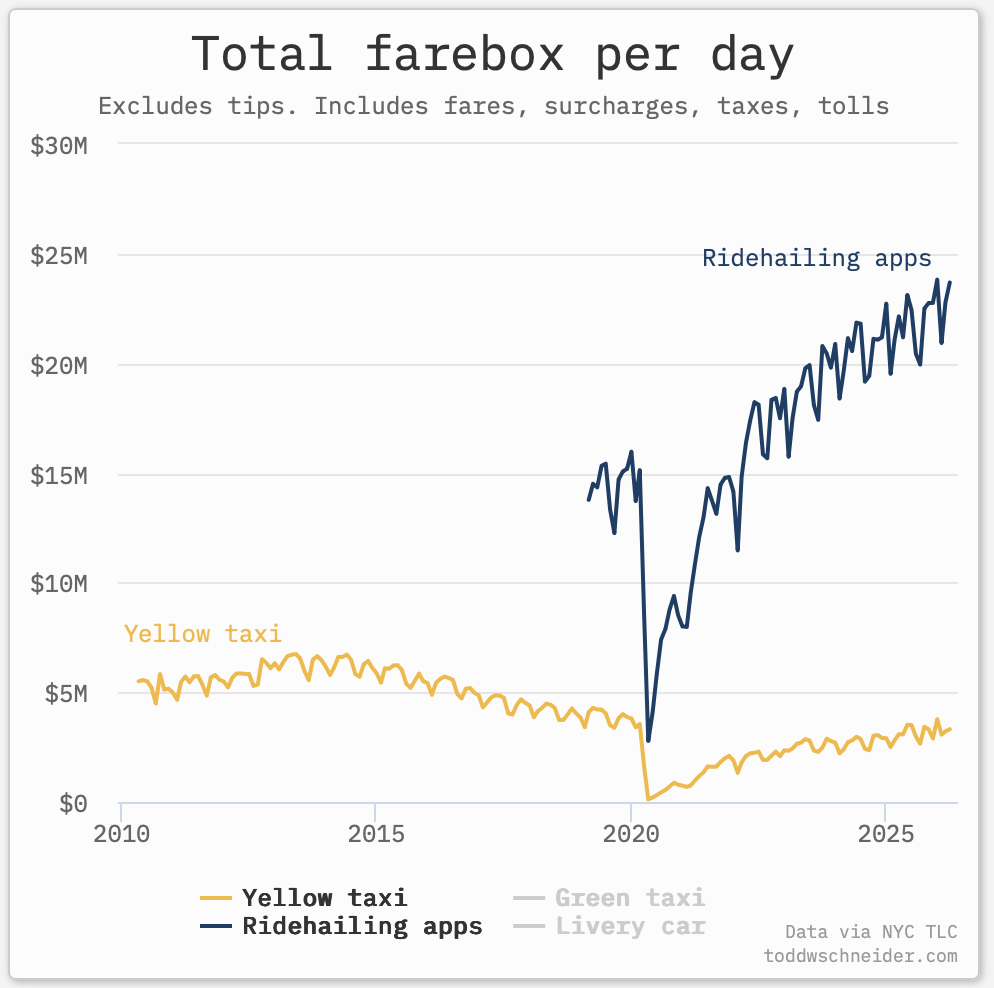
(Source: Todd Schneider / MTA)
Narrowly, then, the problem with using things like O*NET to try to analyse what a job is and how much it can be automated is that this tells you nothing about all the ways that the job shrinks and grow with automation, and the ways that the job itself might be changed by automation elsewhere, outside your analysis.
But I think there's a more fundamental problem, too. Even if you set aside the question of change, I don't think it's possible, in principle, to create a usefully complete description of what the job is.
Reading O*NET descriptions of jobs reminds me a lot of the failure of expert systems, when people thought that you could use logical steps to build an AI system to do image recognition or language translation. Theoretically, you can describe a series of steps by which a machine can recognise a cat, and theoretically, you can write down exactly what an associate partner at a law firm does, but in reality, these things are just too complex or too subtle for us to be able to describe them like that. Sometimes, of course, the job really is just a task, that can be turned into a button, but that's actually pretty rare. Generally, the job is a complex mesh of things that we lack the capability to explain explicitly (tangentially, this is also why most people seem to struggle to use chatbots). And, of course, once you dig into the detail these descriptions fall apart, just as logical systems did before machine learning: apparently administering a family trust and running a desk at a quant fund are comparable jobs, and they need fluency in Lotus 1-2-3, Oracle or Quickbooks but not Bloomberg.
Aaron Levie, CEO of Box, described this as a variant of ‘Gell-Mann Amnesia’. You have a pretty good sense of how complex your own field is, and how incomplete AI’s addressability of that might be, but in other fields you forget this - you see a Claude template for a Powerpoint or a legal draft and you think “wow, consultants and law firms are screwed!” When you hire Bain, BCG or McKinsey, they will give you some slides, but that’s not what you’re paying for, just as when you buy software, you’ll get some code, but that’s not the product.
The counter-argument to all of this would be to say that, yes, well done, there are important exceptions, as there always are, but directionally and in aggregate, it is ‘surely’ correct to say that jobs that involve a lot of repetitive clerical work are most exposed, and this is how many jobs that is, and by how much. That sounds good, but you don’t know if the exceptions are bigger than the rule. Suppose we’d looked at the internet in 1995 and said that this would destroy the value of physical distribution for media - this was ‘directionally correct’, but in practice that meant totally different things for record companies, newspapers, TV companies and movie studios. Are you trying to say something that has some predictive value, or just observing a truism? On average, we’re all dead. Half of the jobs you’ve analysed might be entirely unaffected, and there might be other big pools of jobs to be transformed that you miss entirely. You don’t know.
A while ago, I noted someone had criticised my work by saying that I always end by saying ‘it depends’. But when you're at such an early stage of a fundamentally new technology, any specific predictions about a particular field will only be correct by luck: it really does depend. As Yogi Berra said, “it’s tough to make predictions, especially about the future”. We can certainly point to framings and mental models for how this might work, and we can point to what happened the last half-dozen times we went through this kind of change. We can even say things that are probably directionally correct. But as soon as you try to quantify that, and model it out job by job and industry by industry, and make pretty radar charts, you’re fooling yourself, because you do not actually know what those jobs are today, and you do not know how they will change. At a minimum, you have to ask whether your model passes the newspaper test, the Uber test and the CPA test: would your approach have captured those effects? If not, how useful is it to the rest of us?